As Wikipedia gives it
Suppose you’re on a game show, and you’re given the choice of three doors: Behind one door is a car; behind the others, goats. You pick a door, say No. 1, and the host, who knows what’s behind the doors, opens another door, say No. 3, which has a goat. He then says to you, “Do you want to pick door No. 2?” Is it to your advantage to switch your choice?
Under what Wikipedia calls “the standard assumptions”, you should switch. The standard assumption is that the host will always open a door, and it will always be a door with a goat behind it.
One of my colleagues doesn’t believe the standard assumptions are reasonable. What I want to look at here is what should you do based on any observed history of the game – and if the standard assumptions are in fact true, how fast will you learn that switching is the right decision?
I’ll start out with you assuming that the host always opens a door so his only choice depending on your actions is which of the doors to open. If you’ve chosen the car it doesn’t matter which door he opens; if you’ve chosen a goat he has a probability \(p\) of opening the door with the car. I’ll also pretend we only know what’s behind the door he opens, when in fact we learn about all the doors (this doesn’t matter in the long run). You should switch if \(p<0.5\).
We could consider just a prior supported on \(p=0.5\) (door chosen at random) and \(p=0\) (the standard assumption), or we can use a prior over all of \([0,\,0.5]\) or even all of \([0,\,1]\). Let’s use a uniform on all of \([0,\,1]\). In 2/3 of cases the car won’t be behind your door, so it’s behind his door with probability \(p\), in the other 1/3 of cases you’ve got the car, so it’s behind his door with probability 0. Suppose we run the game a few times and the host never opens a door with a car behind it. The posterior distribution of \(p\) (by numerical quadrature) is
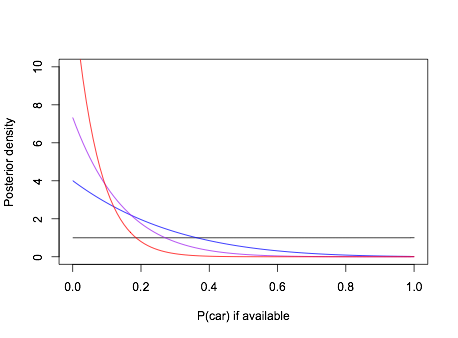
image
So if the standard assumptions are true, contestants should learn quickly that \(p\) is small.
It’s more dramatic than that, though: under this prior you should be indifferent between switching and not switching. Seeing even one run where a car could have been revealed, and wasn’t, would be enough to make your posterior expected utility favour switching. In order not to favour switching after a few shows, you’d need a prior that was strongly in favour of either \(p=0.5\) or \(p>0.5\). So, if the standard assumptions are true, rational players will quickly learn to switch.
It might be, though, that you don’t assume the host has to open a door. You’ve now got three parameters: the probability \(q_1\) of opening a door if you’ve chosen the car, the probability \(q_2\) of opening the door with the other goat if you’ve chosen a goat, and the probability \(q_3\) of opening the door with the car if he doesn’t open the door with the goat. The standard assumptions are \(q_1=1\), \(q_2=1\), \(q_3=0\)
The Nash equilibrium, according to Wikipedia, is \(q_1=0\), \(q_2=0\), \(q_3=0\) for the host, and not switching for the player. On the other hand, If the standard assumptions are true, we’ll know after seeing one game that the host isn’t playing the minimax strategy – in fact, even the first contestant will know.
With this parametrisation, \(q_1/3\) is the joint probability you have the car and the host reveals a goat, and \(2q_2/3\) is the joint probability you have a goat and the host reveals the other goat. So, conditional on seeing a goat you should switch if \(q_1<2q_2\). A flat prior implies switching even for the first contestant. To get extreme, suppose we had a \(\textrm{Beta}(10,1)\) prior for \(q_1\) and a \(\textrm{Beta}(1,10)\) prior for \(q_2\). If the standard assumptions are true, we still learn that switching is better after 7 rounds more often than not, and by ten rounds almost all the time.
In summary, if there’s an opportunity to watch even a few rounds of the game before playing, you don’t need to argue with someone about whether the standard assumptions are true. Just watch and learn.